.png)

让不懂技术人也能看得懂的Stable Diffusion技术解析
Stable Diffusion技术解析
在人工智能领域,Stable Diffusion模型以其革命性的文本到图像生成能力,引领了AI绘画的新潮流。这项技术不仅在学术界引起了广泛关注,也在工业界和艺术创作中展现出巨大的应用潜力。
一、Stable Diffusion模型概述
Stable Diffusion是由CompVis、Stability AI和LAION的研究人员共同开发的文本到图像潜在扩散模型(LDM)。该模型能够根据文本提示生成高质量的图像,其技术亮点在于引入了ControlNet和T2I-Adapter控制模块,显著提升了生成图像的可控性。
二、模型架构与原理
Stable Diffusion模型的架构可以分为三个核心部分:文本编码器、图片信息生成器和图片解码器。这一过程可以概括为:输入文本经过文本编码器转换为语义向量,这些向量随后指导图片信息生成器将噪声图像逐步转化为含有文本信息的图像,最终由图片解码器生成高分辨率的输出图像。
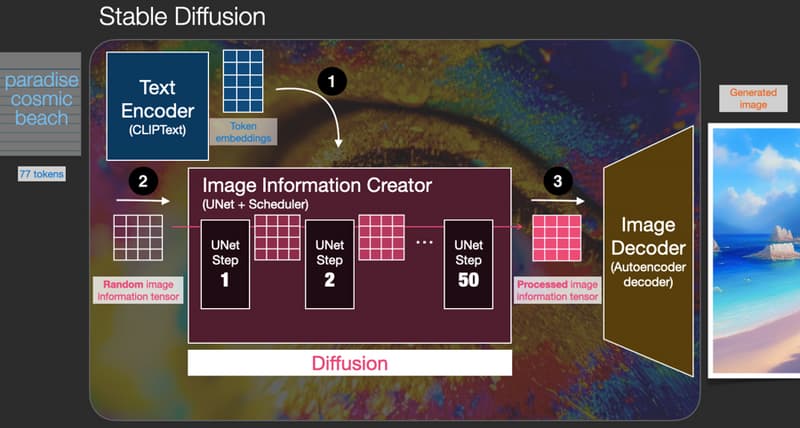
文本编码器(Text Encoder)
文本编码器利用CLIP模型,将输入的文本提示转换为语义向量,这些向量捕获了文本的深层含义,并为图像生成提供必要的语义信息。
图片信息生成器(Image Information Creator)
图片信息生成器是模型的核心,它通过Unet网络和采样器算法共同工作,将低维的噪声向量逐步转化为包含丰富语义信息的图像向量。这一过程称为Diffusion,通过迭代去噪,生成与文本信息相匹配的图像。
图片解码器(Image Decoder)
图片解码器负责将低维的图像向量升维并解码为最终的高分辨率图像。这一步骤是图像生成过程的最终输出,将隐空间的表示转换为直观的像素空间图像。
三、CLIP模型
CLIP框架由两部分组成:视觉编码器和语言编码器,它们的协同工作类似于推荐系统中广泛采用的双塔架构。
在训练阶段,系统会从数据集中随机抽取样本(如果图片与标签相匹配,则被视为正样本;反之,则为负样本),CLIP模型的主要训练任务是判断给定的图文对是否相匹配。 一旦获取到文本和图像,视觉编码器和语言编码器将它们分别转换成两个嵌入向量,即图像嵌入和文本嵌入。
随后,系统利用余弦相似度测量这两个嵌入向量之间的相似性,并根据正负样本的标签与模型预测结果之间的一致性来计算损失函数,该函数用于通过反向传播来优化两个编码器的参数。
训练完成后,CLIP模型能够将匹配的图文对转换成相似的嵌入向量,而对于不匹配的图文对,其编码器输出的向量余弦相似度将趋近于零。 在推理模式下,输入的文本通过文本编码器转换为文本嵌入,同时输入的图像通过图像编码器转换为图像嵌入,这样两者就可以相互影响。在图像生成的采样阶段,文本输入通过文本编码器转换得到的嵌入向量被用作Unet网络的条件输入。
以上说的还是太抽象,可以用一张图理解文字和图片的关系:
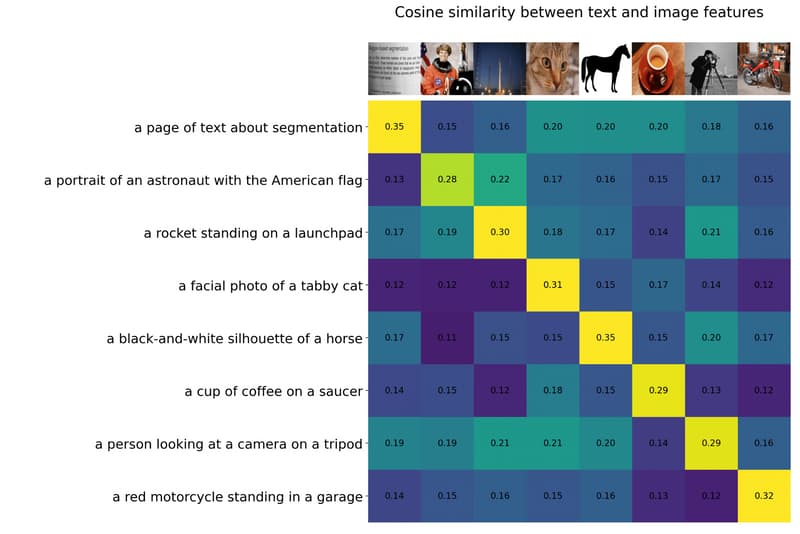
三、Unet网络与训练
Unet网络是Stable Diffusion中的去噪引擎,采用Encoder-Decoder结构,通过DownSample和UpSample进行图像的降维和升维处理。网络的训练目标是学习如何从噪声图像中恢复出清晰的图像,这一过程通过预测噪声并从加噪图像中减去噪声来实现。
 首先整个降噪的过程会在一个 Latent Space(潜空间)里进行,然后会进行多 Steps(步)的降噪,你可以对这个 Steps 进行调整,一般越多图片质量也会好,但时间也会越久。当然这个也跟模型有关,Stable Diffusion XL Turbo 就能 1 步出图。
首先整个降噪的过程会在一个 Latent Space(潜空间)里进行,然后会进行多 Steps(步)的降噪,你可以对这个 Steps 进行调整,一般越多图片质量也会好,但时间也会越久。当然这个也跟模型有关,Stable Diffusion XL Turbo 就能 1 步出图。
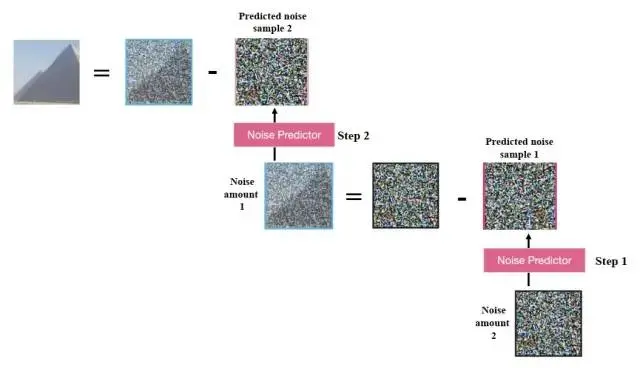 这里详细描述一个预测噪音和去噪的过程。首先根据 seed值随机生成一个噪声图,然后Noise Predictor(噪音预测器)通过输入的文本向量生成一个噪声图,在生成一张不包含文本向量的噪声图,然后用包含向量的噪声图剪去不包含向量的噪声图,得到一张相对接近的噪声图,最后用 seed值随机生成一个噪声图融合这张相对接近的噪声图完成一步去噪的过程。这样经过多步反复去噪之后,形成最终的结果,通过Image Decoder输出我们可看的图片。
这里详细描述一个预测噪音和去噪的过程。首先根据 seed值随机生成一个噪声图,然后Noise Predictor(噪音预测器)通过输入的文本向量生成一个噪声图,在生成一张不包含文本向量的噪声图,然后用包含向量的噪声图剪去不包含向量的噪声图,得到一张相对接近的噪声图,最后用 seed值随机生成一个噪声图融合这张相对接近的噪声图完成一步去噪的过程。这样经过多步反复去噪之后,形成最终的结果,通过Image Decoder输出我们可看的图片。
四、扩散模型与潜空间
扩散模型(DDPM)是Stable Diffusion中的一个关键概念,它通过在图像上不断加噪然后去噪来生成图像。采样器则负责在推理阶段迭代去除噪声,恢复出原始的清晰图像。Diffusion的概念在很早之前就出现,直到Stable Diffusion中使用latent space(潜空间)来处理整个推理阶段,才让这个大模型可以在我们的名用级显卡上运行。
举个好理解的例子,我们如果需要生成512 x 512像素的图像在潜空间为4 x 64 x 64的向量大小。是不是就缩小很多了。在这个空间里计算,获得的结果集,再给Image Decoder还原出肉眼看到的图片。
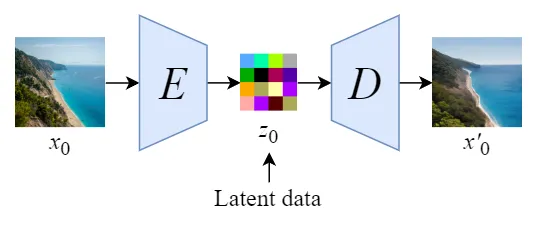
五、Image Decoder
在将图片进行训练时,将图片训练成向量,会使用到Image Encoder,再将潜空间向量还原成图片的过程会用到Image Decoder,我们统称为Variational Auto Encoder(变分自编码器)简称VAE。
六、技术挑战与未来展望
尽管Stable Diffusion技术在图像生成领域取得了显著进展,但仍面临一些技术挑战,如提高生成图像的多样性和质量。随着技术的不断发展,预计AI绘画将在更多领域展现其独特的价值和潜力。