


通过 Ollama,您可以在本地运行各种大型语言模型(LLM)并从中生成文本。Spring AI 通过 OllamaChatModel API 支持 Ollama 的聊天补全功能。
Ollama 还提供 OpenAI API 兼容端点。OpenAI API 兼容性部分解释了如何使用 Spring AI OpenAI 连接到 Ollama 服务器。
先决条件
您首先需要访问 Ollama 实例。有几种选项:
在本地机器下载并安装 Ollama
通过 Testcontainers 配置和运行 Ollama
通过 Kubernetes 服务绑定连接到 Ollama 实例
您可以从 Ollama 模型库拉取要在应用程序中使用的模型:
ollama pull <模型名称>您也可以拉取数千个免费的 GGUF Hugging Face 模型:
ollama pull hf.co/<用户名>/<模型仓库>或者,您可以启用自动下载所需模型的选项:自动拉取模型。
自动配置
Spring AI 自动配置和 starter 模块的构件名称已发生重大变更。请参考升级说明获取更多信息。
Spring AI 为 Ollama 聊天集成提供 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Maven pom.xml 或 Gradle build.gradle 构建文件:
Maven
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>Gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-ollama'
}
参考依赖管理部分将 Spring AI BOM 添加到构建文件。
基础属性
前缀 spring.ai.ollama 是配置到 Ollama 连接的属性前缀。
以下是初始化 Ollama 集成和自动拉取模型的属性:
聊天属性
聊天自动配置的启用和禁用现在通过顶级属性配置,前缀为 spring.ai.model.chat。
启用:spring.ai.model.chat=ollama(默认启用)
禁用:spring.ai.model.chat=none(或任何不匹配 ollama 的值)
此变更允许配置多个模型。
前缀 spring.ai.ollama.chat.options 是配置 Ollama 聊天模型的属性前缀。它包括 Ollama 请求(高级)参数(如模型、keep-alive 和格式)以及 Ollama 模型选项属性。
以下是 Ollama 聊天模型的高级请求参数:
其余选项属性基于 Ollama 有效参数和值以及 Ollama 类型。默认值基于 Ollama 类型默认值。
所有以
spring.ai.ollama.chat.options为前缀的属性可在运行时通过向 Prompt 调用添加请求特定的运行时选项来覆盖。
运行时选项
OllamaOptions.java 类提供模型配置,如使用的模型、温度等。
启动时,可通过 OllamaChatModel(api, options) 构造函数或 spring.ai.ollama.chat.options.* 属性配置默认选项。
运行时可通过在 Prompt 调用中添加新的请求特定选项来覆盖默认选项。例如为特定请求覆盖默认模型和温度:
ChatResponse response = chatModel.call(
new Prompt(
"生成 5 位著名海盗的名字。",
OllamaOptions.builder()
.model(OllamaModel.LLAMA3_1)
.temperature(0.4)
.build()
));除模型特定的 OllamaOptions 外,您还可使用通过 ChatOptionsBuilder#builder() 创建的可移植 ChatOptions 实例。
自动拉取模型
当模型在 Ollama 实例中不可用时,Spring AI Ollama 可以自动拉取模型。此功能对开发和测试以及将应用程序部署到新环境特别有用。
您还可以按名称拉取数千个免费的 GGUF Hugging Face 模型。
有三种拉取模型的策略:
always(在PullModelStrategy.ALWAYS中定义):即使模型已存在也始终拉取。确保使用模型最新版本。when_missing(在PullModelStrategy.WHEN_MISSING中定义):仅当模型不存在时拉取。可能导致使用较旧版本的模型。never(在PullModelStrategy.NEVER中定义):从不自动拉取模型。
注意:
由于下载模型可能有延迟,不推荐在生产环境中自动拉取。应预先评估并预下载所需模型。
应用程序在指定模型在 Ollama 中可用前不会完成初始化。根据模型大小和互联网连接速度,可能显著减慢应用程序启动时间。
您可以通过配置属性配置拉取策略、超时和最大重试次数:
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1可在启动时初始化额外模型,这对运行时动态使用的模型很有用:
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5如果希望仅对特定类型模型应用拉取策略,可从初始化任务中排除聊天模型:
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: false此配置将对除聊天模型外的所有模型应用拉取策略。
函数调用(Function Calling)
您可向 OllamaChatModel 注册自定义 Java 函数,使 Ollama 模型智能选择输出包含参数的 JSON 对象来调用一个或多个注册函数。这是将 LLM 能力与外部工具和 API 连接的强大技术。阅读更多关于工具调用的信息。
要求:
函数调用需 Ollama 0.2.8 或更高版本
流式模式中的函数调用需 Ollama 0.4.6 或更高版本
多模态
多模态指模型同时理解和处理多种来源信息的能力,包括文本、图像、音频、数据格式。
Ollama 中支持多模态的部分模型包括 LLaVA 和 BakLLaVA(参见完整列表)。更多细节请参考 LLaVA: 大型语言和视觉助手。
Ollama 消息 API 提供 "images" 参数以在消息中包含 base64 编码图像列表。
Spring AI 的 Message 接口通过引入 Media 类型支持多模态 AI 模型。此类型包含消息中媒体附件的数据和信息,使用 Spring 的 org.springframework.util.MimeType 和用于原始媒体数据的 org.springframework.core.io.Resource。
以下是 OllamaChatModelMultimodalIT.java 中提取的简单代码示例,展示用户文本与图像的组合:
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage("解释你在这张图片中看到了什么?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage,
OllamaOptions.builder().model(OllamaModel.LLAVA)).build());此示例展示模型以 multimodal.test.png 图像作为输入:

附带文本消息"解释你在这张图片中看到了什么?",并生成类似响应:
图像显示了一个装满成熟香蕉和红苹果的小金属篮。篮子放置在表面上,似乎是桌子或台面,背景中隐约可见类似厨房橱柜或抽屉的东西。篮子后面还有一个金色环状物可见,表明此照片拍摄于有金属装饰或固定装置的区域。整体环境暗示一个家庭环境,水果可能为方便或美观而展示。
结构化输出
Ollama 提供自定义结构化输出 API,确保模型生成严格符合您提供的 JSON Schema 的响应。除了现有的 Spring AI 模型无关结构化输出转换器外,这些 API 还提供增强的控制和精确度。
配置
Spring AI 允许您通过 OllamaOptions 构建器以编程方式配置响应格式。
使用聊天选项构建器
如下所示,您可以使用 OllamaOptions 构建器设置响应格式:
String jsonSchema = """
{
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": { "type": "string" },
"output": { "type": "string" }
},
"required": ["explanation", "output"],
"additionalProperties": false
}
},
"final_answer": { "type": "string" }
},
"required": ["steps", "final_answer"],
"additionalProperties": false
}
""";
Prompt prompt = new Prompt("如何解方程 8x + 7 = -23",
OllamaOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.format(new ObjectMapper().readValue(jsonSchema, Map.class))
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);与 BeanOutputConverter 工具集成
您可以利用现有的 BeanOutputConverter 工具从领域对象自动生成 JSON Schema,然后将结构化响应转换为领域特定实例:
record MathReasoning(
@JsonProperty(required = true, value = "steps") Steps steps,
@JsonProperty(required = true, value = "final_answer") String finalAnswer) {
record Steps(
@JsonProperty(required = true, value = "items") Items[] items) {
record Items(
@JsonProperty(required = true, value = "explanation") String explanation,
@JsonProperty(required = true, value = "output") String output) {
}
}
}
var outputConverter = new BeanOutputConverter<>(MathReasoning.class);
Prompt prompt = new Prompt("如何解方程 8x + 7 = -23",
OllamaOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.format(outputConverter.getJsonSchemaMap())
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);
String content = this.response.getResult().getOutput().getText();
MathReasoning mathReasoning = this.outputConverter.convert(this.content);注意:使用
@JsonProperty(required = true,…)注解生成准确标记字段为必需的 schema。虽然这对 JSON Schema 是可选的,但建议使用以确保结构化输出正常工作。
OpenAI API 兼容性
Ollama 兼容 OpenAI API,您可以使用 Spring AI OpenAI 客户端与 Ollama 通信并使用工具。为此,需要将 OpenAI 基础 URL 配置为 Ollama 实例:spring.ai.openai.chat.base-url=http://localhost:11434 并选择提供的 Ollama 模型之一:spring.ai.openai.chat.options.model=mistral。
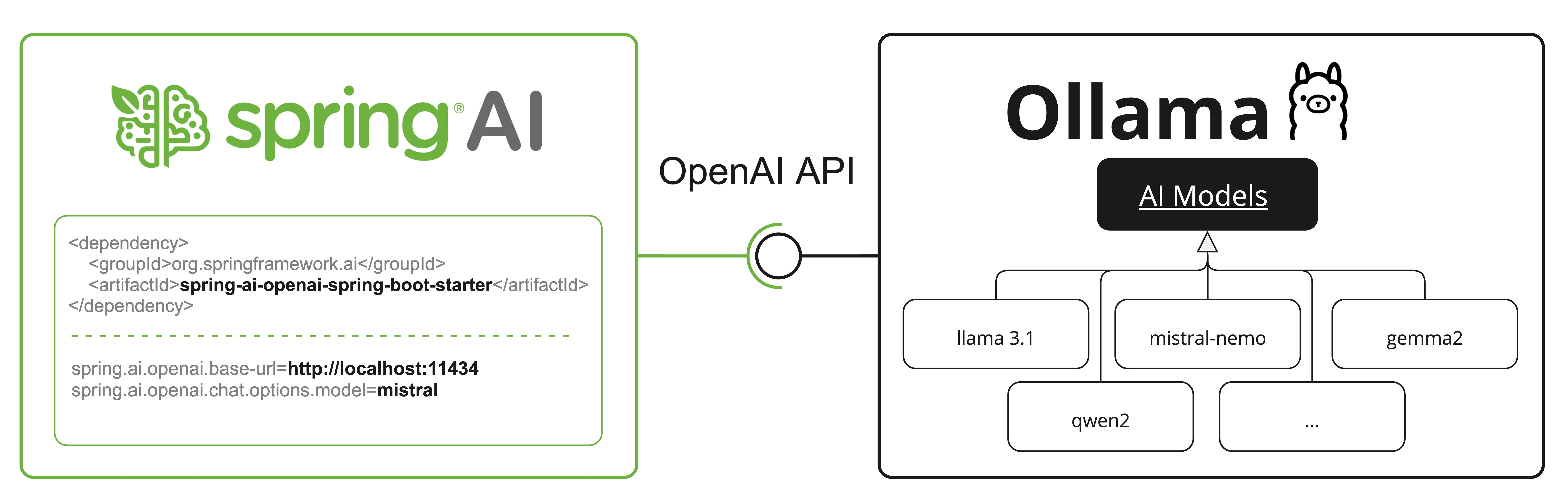
有关通过 Spring AI OpenAI 使用 Ollama 的示例,请参阅 OllamaWithOpenAiChatModelIT.java 测试。
HuggingFace 模型
Ollama 可开箱即用地访问所有 GGUF Hugging Face 聊天模型。您可以按名称拉取任何这些模型:ollama pull hf.co/<用户名>/<模型仓库> 或配置自动拉取策略:自动拉取模型:
spring.ai.ollama.chat.options.model=hf.co/bartowski/gemma-2-2b-it-GGUF
spring.ai.ollama.init.pull-model-strategy=alwaysspring.ai.ollama.chat.options.model:指定要使用的 Hugging Face GGUF 模型spring.ai.ollama.init.pull-model-strategy=always:(可选)在启动时启用自动模型拉取。对于生产环境,应预下载模型以避免延迟:ollama pull hf.co/bartowski/gemma-2-2b-it-GGUF
示例控制器
创建新的 Spring Boot 项目,并将 spring-ai-starter-model-ollama 添加到您的 pom(或 gradle)依赖项。
在 src/main/resources 目录下添加 application.yaml 文件以启用和配置 Ollama 聊天模型:
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: mistral
temperature: 0.7将 base-url 替换为您的 Ollama 服务器 URL。
这将创建 OllamaChatModel 实现,您可将其注入到您的类中。以下是使用聊天模型进行文本生成的简单 @RestController 类示例:
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "讲个笑话") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "讲个笑话") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}手动配置
如果不想使用 Spring Boot 自动配置,可以在应用程序中手动配置 OllamaChatModel。OllamaChatModel 实现 ChatModel 和 StreamingChatModel,并使用低级 OllamaApi 客户端连接到 Ollama 服务。
要使用它,请将 spring-ai-ollama 依赖项添加到项目的 Maven pom.xml 或 Gradle build.gradle 构建文件:
Maven
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>Gradle
dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}参考依赖管理部分将 Spring AI BOM 添加到构建文件。spring-ai-ollama 依赖项还提供对 OllamaEmbeddingModel 的访问。有关 OllamaEmbeddingModel 的更多信息,请参考 Ollama 嵌入模型部分。
接下来,创建 OllamaChatModel 实例并使用它发送文本生成请求:
var ollamaApi = OllamaApi.builder().build();
var chatModel = OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaOptions.builder()
.model(OllamaModel.MISTRAL)
.temperature(0.9)
.build())
.build();
ChatResponse response = this.chatModel.call(
new Prompt("生成 5 位著名海盗的名字。"));
// 或使用流式响应
Flux<ChatResponse> response = this.chatModel.stream(
new Prompt("生成 5 位著名海盗的名字。"));OllamaOptions 为所有聊天请求提供配置信息。
低级 OllamaApi 客户端OllamaApi 为 Ollama 聊天补全 API 提供轻量级 Java 客户端。
以下类图说明 OllamaApi 聊天接口和构建块:
OllamaApi 聊天补全 API 图
注意:
OllamaApi是低级 API,不建议直接使用。应改用OllamaChatModel。
以下是编程使用 API 的简单片段:
OllamaApi ollamaApi = new OllamaApi("您的_主机:您的_端口");
// 同步请求
var request = ChatRequest.builder("orca-mini")
.stream(false) // 非流式
.messages(List.of(
Message.builder(Role.SYSTEM)
.content("您是一名地理老师。正在与学生交谈。")
.build(),
Message.builder(Role.USER)
.content("保加利亚的首都是什么?面积多大?国歌是什么?")
.build()))
.options(OllamaOptions.builder().temperature(0.9).build())
.build();
ChatResponse response = this.ollamaApi.chat(this.request);
// 流式请求
var request2 = ChatRequest.builder("orca-mini")
.ttream(true) // 流式
.messages(List.of(Message.builder(Role.USER)
.content("保加利亚的首都是什么?面积多大?国歌是什么?")
.build()))
.options(OllamaOptions.builder().temperature(0.9).build().toMap())
.build();
Flux<ChatResponse> streamingResponse = this.ollamaApi.streamingChat(this.request2);
评论区